I was under impression I'm quite clear... I don't think the decision made by authors correct.
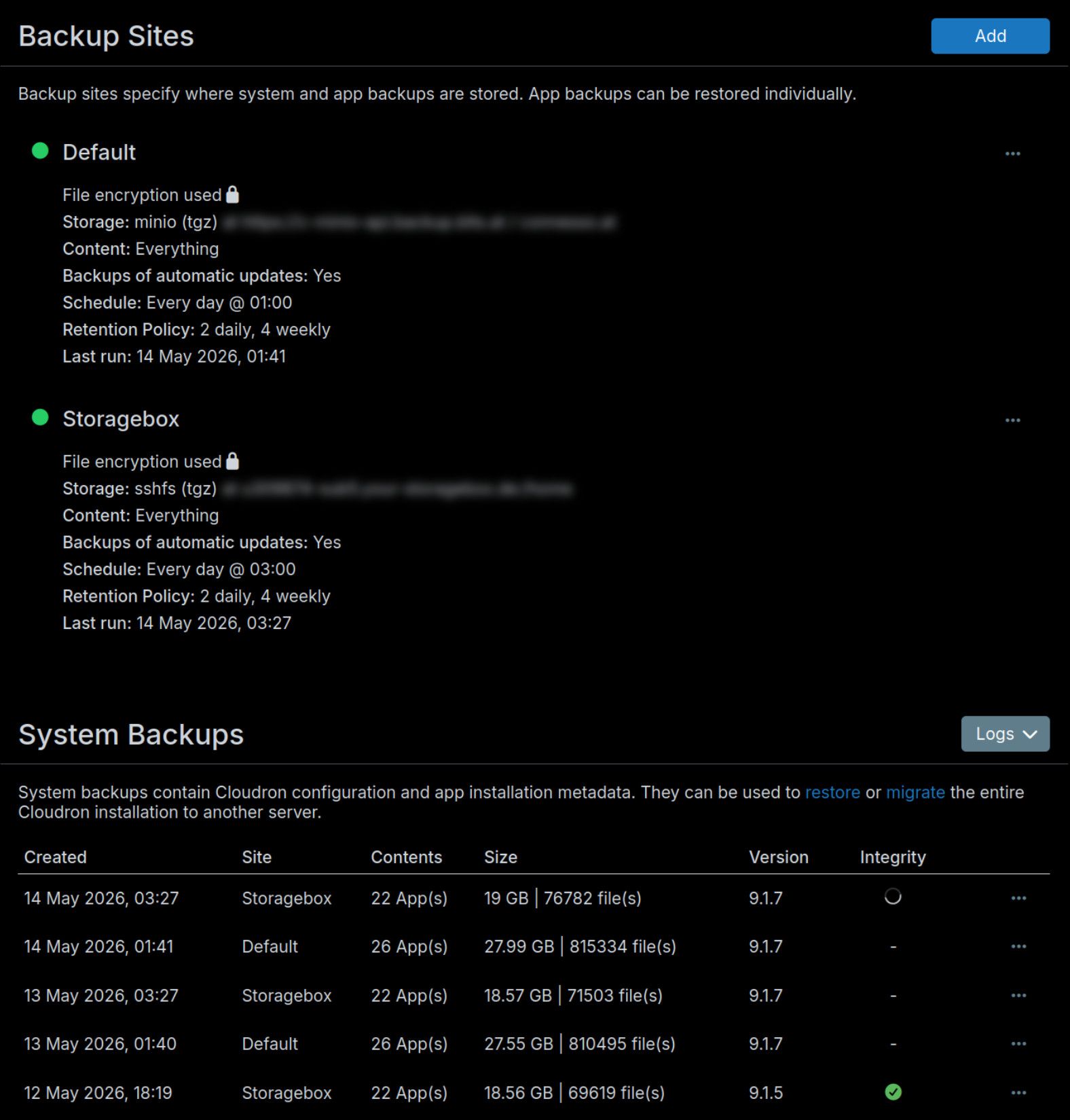
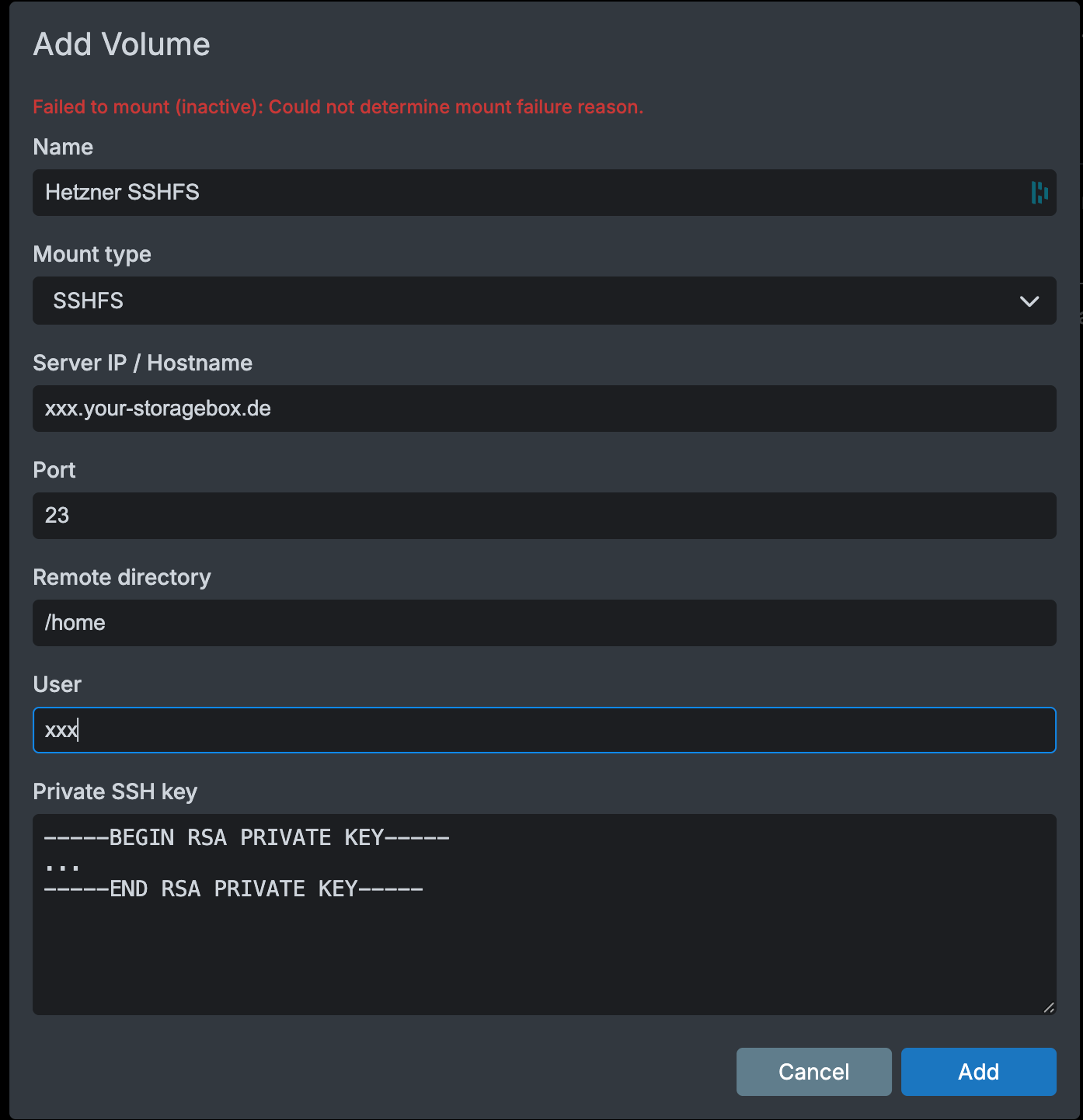
I'm forced to do the backup, even though there is no technical requirement for that. I'm forced to do the backup the way authors want, even though I have my remedies.
As a result, I've just found out one Cloudron instance seriously out of date with a Docker security vulnerability in it. Just because authors decided that I have to have a backup to have automatic backup - to have my systems up to date.
Not sure I follow that...