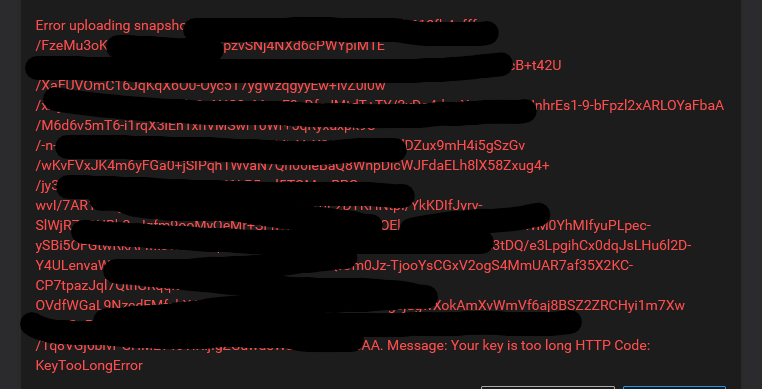
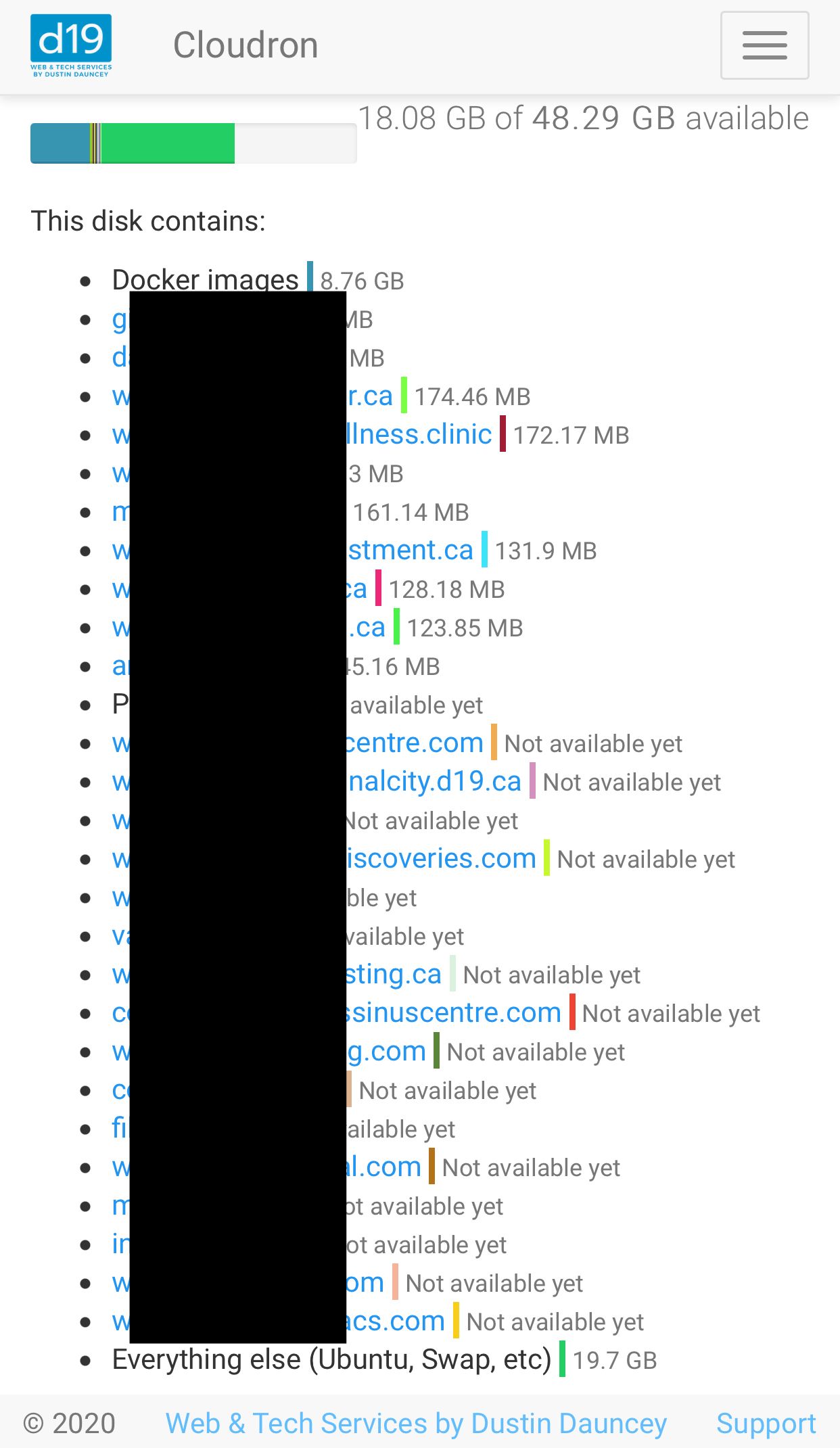
@girish I guess I'm wondering though why it'd say "Not available yet"... is that because I had restarted the server a few hours earlier? I don't normally notice that though when I restart, it usually still shows data. Is it possible there's a bug here?
If the restarts are losing that data, then I'd think that's a bug, right, if it shows for some services but not all? To me that makes it seems like it's either not completing properly when it runs and that could maybe explain why it shows values for some but not all, or perhaps it's losing data when it should be remembering it. My gut tells me there's a bug here. Or am I way off?
I guess it's okay since we have a workaround to run that command when it happens, my brain is just wondering why it happened in the first place and how it could be prevented.